Несмотря на такое большое информационное пространство как Интернет, далеко не всегда удается найти нужную информацию по конкретной проблеме. С этим знаком практически каждый программист. В предлагаемой серии статей я решил поделиться своим собственным опытом по решению различных ситуаций, с которыми сталкивался в реале, а часть обсуждаемых вопросов поднимали мои знакомые или обращались читатели. Все опробовано на практике.
В рамках этой серии я буду затрагивать в основном вопросы программирования на C#, PHP, JS(jQuery), AS, работы с БД MySQL и всевозможных сопутствующих технологий. В общем, веб и базы данных.
C#. Решение проблем с Excel. Экспорт данных в xls/xlsx
Довольно часто программистам ставят задания по написанию программ автоматического обновления баз данных с возможностями импорта/экспорта Excel-файлов. Нужно сказать, что несмотря на множество предлагаемых в интернете решений, подводных камней на этапе реализации именно импорта/экспорта можно встретить довольно много. Также стоит отметить, что некоторые из вариантов хоть и дают ожидаемый результат, но имеют некоторые ограничения, например, по тем же версиям Microsoft Office и форматам (только xls и т.п.), а экспорт в Excel-файл при большом объеме данных может занять довольно продолжительное время. Например, та же многими любимая библиотека + подключаемый программный блок ExcelXMLWriter при создании xls-файла с большим объемом данных требует длительное время на произведение расчетов (десятки минут и более).
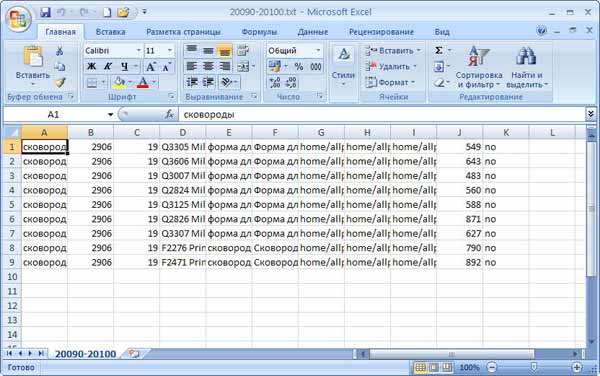
Я прошел довольно интересный путь с использованием различных реализаций импорта/экспорта в Excel и, в конце концов, остановился на наиболее приемлемом для меня варианте, а именно, сохранение результатов работы своих программ в текстовый формат TSV. Это специальный формат для хранения баз данных, который довольно часто используется в различного рода ПО, именно там я его и подсмотрел. В качестве символьного разделителя в TSV используется символ табуляции, записи в полях могут заключаться в двойные или одинарные кавычки (хотя это может и не использоваться), а одна строка текстового файла соответствует одной строке в таблице БД. А в целом, для реализации вы используете стандартный StreamWriter. Вариант TSV открывается любой современной версией Microsoft Excel, автоматически преобразуется в структурированную таблицу, но и здесь есть некоторые тонкие нюансы, которые нужно устранить.
Если вы используете двойные либо одинарные кавычки для выделения записей в строке, то их (эти кавычки) лучше удалить внутри самих записей во избежание дальнейших проблем с чтением в Excel’е. Это целесообразнее сделать, используя класс StringBuilder и его метода Replace(). Замена символов с использованием StringBuilder производится быстрее, нежели просто через класс String, что становится ощутимо при обработке большого количества данных. Также проблему могут вызывать записи, в которых есть разбиение по строкам или абзацам, поэтому нужно обработать и их.
Пример кода необходимых преобразований в записях (двойные кавычки заменяются на одинарные, переход на новую строку — на HTML-тег <br/>, два пробела — на один, символ табуляции — на четыре HTML-символа пробела):
static string ubratKav(string p) { StringBuilder b = new StringBuilder(p); b.Replace("\"", "\'"); b.Replace(Environment.NewLine, "<br/>"); b.Replace("\n", "<br/>"); b.Replace(" ", " "); b.Replace("\t", " "); return b.ToString(); }
Использование TSV выгодно еще и тем, что вы можете использовать данный формат и в обход Excel, например, написав собственный небольшой модуль импорта/экспорта, но не Excel-файлов, а вашего формата — обыкновенного текстового TSV из которого построчно извлекаются данные и затем парсятся.
Excel автоматически распознает TSV-формат
C#. Решение проблем с Excel. Импорт данных из xls/xlsx
Что же касается импорта данных из xls либо xlsx файлов, то наиболее часто встречаемый «подводный камень» — неправильная обработка данных при чтении. Да, это есть и встречается довольно часто. Например, артикулы товаров могут иметь как буквенную, так и цифровую маркировку. И если вы будете использовать стандартную библиотеку, такую как, например, Microsoft.Jet.OLEDB4.0, то она будет читать в колонке либо только буквенные, либо только числовые артикула, это можно обнаружить при загрузке Excel-файла в DataGridView — вместо части данных пустые поля.
Как отличный вариант, решающий данную проблему, можно рассматривать замену «читающей» библиотеки на Microsoft.ACE.OLEDB 12.0. Ее можно найти в рамках системного драйвера для Office 2007 — AccessDatabaseEngine (скачивается по адресу http://www.microsoft.com/en-us/download/details.aspx?id=23734). Устанавливается в папку, где у вас находится Microsoft Office, а к C#-проекту его нужно подключить в References, взяв ddl-ку из этого же каталога. Затем все стандартно (в данном случае вы выбираете файл через OpenFileDialog):
const string CONNECTION_STRING = @"Provider=Microsoft.ACE.OLEDB.12.0;Data Source = {0};Extended Properties=Excel 8.0;"; private const string QUERY_EXCEL = "SELECT * FROM[Лист1$]"; string connection_String = string.Format(CONNECTION_STRING, openFileDialog1.FileName); OleDbDataAdapter adapter = new OleDbDataAdapter(QUERY_EXCEL, connection_String); DataTable dataTable = new DataTable(); adapter.Fill(dataTable); dataGridView.DataSource = dataTable;
В какой программе можно менять кодировку файлов?
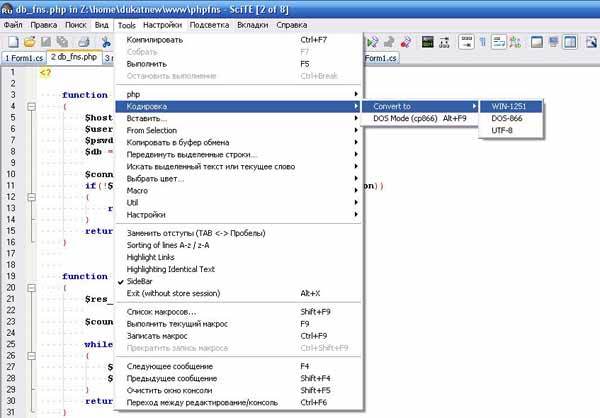
Вопрос говорит сам за себя, если ваша используемая вами программа, фреймворк или среда разработки не предусматривает замену кодировки (а наиболее частые проблемы возникают с преобразованиями 1251 в UTF8 и обратно). Например, вы скачали сторонний модуль на PHP или JS, который при подключении к вашему сайту вместо кириллицы выдает «кракозябры» либо знаки вопроса. Эту проблему поможет решить последняя версия бесплатного редактора для программистов — sCite. В главном меню кликаем на опции Tools, далее Tools -> Кодировка -> Convert to и выбираем нужный нам вариант.
Изменение кодировки файлов в программе sCite
Если честно, открою свой секрет, я использую sCite как основной рабочий инструмент, когда пишу что-то на PHP или JS, верстаю HTML, либо конфигурирую CSS, то есть никаких фрейморков и т.п. Этого вполне достаточно для написания CMS любого уровня сложности (это 50% моей нынешней работы). Поэтому небольшое отступление…
Несколько слов об оптимизации скорости (ИМХО)
Сам нативный PHP не является пределом совершенства, для обеспечения скорости работы движков своих сайтов я даже переписываю его некоторые базовые «вроде бы удобные» функции вручную и заново, потому как они значительно влияют на скорость обработки данных, следовательно, и на время загрузки страниц, в которых имеется сложный и многочисленный контент. Чуть больше, чем в половине заказов, связанных с переделками уже существующего кода CMS, я решал конкретные проблемы скорости, перенося функции обработки на уровень MySQL. Очень многое можно в вопросах оптимизации можно сделать при правильной постановке SQL-запросов к базе данных, и при этом методом проб и ошибок сравнивать ту же скорость обработки средствами PHP и SQL (SQL, конечно, нужно изучить на уровне профи, потому как в большинстве случаев по скорости обработки данных его использование выигрывает).
Не бойтесь оптимизировать запросы, создавая функции, которые выбирают только те поля из таблицы БД, которые вам нужны в конкретной ситуации. Пусть это добавит пару строчек кода в файле с ключевыми PHP-функциями, но представьте, какой это дает выигрыш при обработке 10 тыс. и более товаров. Объясняя простым PHP-языком, та же функция mysql_fetch_array() или ее подобные, возвращает массив с гораздо меньшим объемом. Зачем загружать в массив все значения таблицы БД, если нам, по сути, нужно обрабатывать только несколько полей из нее. Это всегда касается случаев, когда запрос SELECT для таблицы БД является базовым для исполняемых PHP-скриптов вывода текущей страницы.
Идем дальше. Давайте рассмотрим практический реальный пример: на одной странице должны обрабатываться и выводиться данные по 120 позициям товаров (30-40 в главной таблице, остальные в слайдерах типа «Хиты продаж», «Новые поступления» и так далее). Явный пример «тяжелой функции», которую так любят использовать — htmlspecialchars(). Многие её автоматически подключают при выводе данных на страницу. Но, если вы примените htmlspecialchars() для всех имен, кратких описаний, описаний и т.п., то скорость загрузки страницы ощутимо увеличится. Поэтому такую функцию удобнее всего использовать на незначительных элементах (вводе комментариев через что-то типа TinyMCE, либо же в админ-панели). А потом продумать, как будет функционировать ваша система. То есть, в админ-панели при апдейте или добавлении товара вы, конечно, используете htmlspecialchars(), потому как ввод там делается через WYSIWYG-редактор.
Если вы импортируете в вашу БД сканерами/парсерами/роботами-пауками чужие сайты-доноры, добавляете данные из Excel-файлов, либо просто переносите стороннюю БД нужного формата (например, одного из поставщиков), то замены типа «\»» на «"» и т.п. у вас должны присутствовать сразу в коде. Это нужно предусматривать автоматически. Если такового нет, то просто «перелопатьте» БД подобными заменами, оно себя окупит. В результате на странице вывода вы не будете использовать дополнительную функцию преобразования htmlspecialchars(), которая, по сути, если все вышеперечисленное не соблюдено, включается для каждого товара. Это конкретная оптимизация скорости.
Другими словами, во всём, что касается единичных вводимых элементов, включая работу в админ-панели, можно использовать «тяжелые» функции, на фронт-энд должны подаваться уже заранее подготовленные данные. Не усердствуйте с фронт-эндом!
И еще один вопрос, который бы хотелось затронуть в области PHP — это шаблоны. Ко мне часто обращаются с вопросами добавления функционала для сайтов на различных CMS, но если говорить об интернет-магазинах (исключая «творческих поделок» на бесплатных движках типа… не буду говорить), то в рамках серьезных проектов чаще всего приходилось сталкиваться с клонами бесплатной версии Shop-Sript FREE, в которой за базис взят Smarty. М-да, Smarty...
Вообще, программеры из webAsyst (авторы Shop-Script) сделали капитальную работу (хотя я не уверен, что коды на базе старенького Shop-Sript FREE нормально проходили верификацию, с коммерческими версиями не сталкивался). Думаю, что у них сейчас все удачно и желаю им всяких благ. Но, например, большинство вопросов от заказчиков апгрейда касалось скорости загрузки страниц на фронт-энде, а самым слабым местом в Shop-Sript FREE является генерация древовидного меню, и, хотя там, вроде бы, простая функция за это отвечает, при большом количестве разделов и подразделов, все жутко тормозит.
Вариант решения ситуации — реорганизация БД таким образом, чтобы таблица каталогов выглядела как хэш-таблица, в которой «дерево каталогов» видно сразу без обработки и обычных/рекурсивных циклов поиска родителей на PHP. Это можно организовать как в самой таблице каталогов, так и в отдельной таблице с прямыми ссылками на, если применять терминологию таблиц Shop-Script FREE, то нужно сделать новую (или добавить в старую), в которой имеются три поля: catalogID, parent и «глубина». «Глубину» можно рассчитывать на уровне обновления в админ-панели. А на фронт-энде — оптимизированные SQL-запросы из имеющейся новой (или оптимизированной) таблицы.
Я бы, конечно, мог бы написать по этой теме целую статью, но не суть… Насчет Smarty, возможно, согласен, что что-то не понял, но мне всегда было нужно, чтобы все быстро обрабатывалось, а тут еще посредники.
В общем, всё довольно весело. Честно сказать, для меня оптимизация сайтов с «классическим MVC представлением» в варианте Smarty — это просто заключение фигурных скобок из PHP или JS в tpl-шаблонах в {literal}{{/literal} и {literal}}{/literal} соответственно.
Все подобное, что делает Smarty, прекрасно реализуется в обычном нативном PHP с использованием include. Вот не понимаю, зачем поверх над интерпретируемым языком (скриптом, коим и является PHP) ставить еще один интерпретируемый язык шаблонов?
Это опять же (в очередной раз) противостояние сторонников процедурного (функционального) программирования и объектно-ориентированного. Учитывая то, что я воспринимаю классы как гетерогенные ассоциативные массивы (великолепный пример — тип table в языке Lua) + хороший пиар, то тут лучше не спорить. Кстати говоря, несложно заметить, что как только языки программирования приближаются к ООП и конкретно к реализации классов, их развитие начинает тормозить, в основном, из-за усложнения простого. Как пример, это заметно по ActionScript 3. C PHP пытаются производить нечто подобное… ИМХО.
Примеры работы моей CMS…
Базовый сайт на момент написания статьи в тестовом режиме… Реализованы блоки из ТЗ
Базовый сайт на момент написания этой статьи в тестовом режиме…
Идем дальше...
Проблема с кодировкой при чтении из БД (MySQL, PHP)
Это довольно часто возникающий вопрос у начинающих. Причем, если мы говорим о местных сервисах, предоставляющих хостинг, то в первую очередь там реализована поддержка cp1251, и иногда могут проявиться проблемы, если у вас БД использует за базис UTF8, с иностранными хостерами наоборот. На самом деле все решается довольно просто. При каждом коннекте к базе нужно прописывать запрос типа: mysql_query("SET NAMES utf8"); или же mysql_query("SET NAMES ‘cp1251’");, в зависимости от того, что вам нужно. Таким образом, стандартная функция запроса в коде PHP, например, должна выглядеть так…
function get_article($id) { db_connect();//ф-я подключения к БД mysql_query("SET NAMES utf8"); $query = ("SELECT * FROM articles WHERE id='$id' "); $result = mysql_query($query); $row = mysql_fetch_array($result); return $row; }
В случае, когда данный вариант не поможет, можно использовать строки, например, для случая с переходом на cp1251:
mysql_query("SET NAMES 'cp1251'"); mysql_query("SET CHARACTER SET 'cp1251'");
Если у вас есть доступ к файлу конфигурации MySQL на сервере, то запросы, организованные таким образом являются излишними. Достаточно указать базовую кодировку в конфигурационном файле my.cnf. В разделе [mysqld] вводим:
default-character-set=cp1251 character-set-server=cp1251 collation-server=cp1251_general_ci init-connect=»SET NAMES cp1251″ skip-character-set-client-handshake
А в раздел [mysqldump] прописываем строку:
default-character-set=cp1251
Идем дальше...
Обновление БД MySQL и ошибка duplicate entry (программирование на C#)
Эта проблема также довольно часто обсуждается на различных форумах. Итак, давайте представим себе стандартную рабочую ситуацию. Например, вы пишете программу, обновляющую таблицу или несколько таблиц вашей БД, используя входные данные из Excel-файлов или чего-нибудь подобного.
Нередко крупные оптовые поставщики дают розничным интернет-магазинам уже подготовленные прайс-листы со ссылками на изображения, которые скачать или заполучить довольно легко. Перед программистами в основном ставится задача обновить существующие в БД позиции товаров и вписать туда новые при условии их отсутствия.
Работа с БД в данном случае может выстраиваться двумя путями, а именно, удаленное соединение с базой данных сайта на сервере, что на самом деле не очень оправданно, в том числе и с точки зрения безопасности и сохранности данных. И второй вариант — импорт таблиц БД на локальный сервер вашего компьютера, например, самым популярным из которых под Windows является Denwer. Этот вариант очень удобен в силу скорости работы, а для отладки работающей программы так просто необходим. Обновив нужные таблицы БД сайта у себя на локальном компьютере, вы можете их потом легко загрузить в БД сайта через ту же панель phpMyAdmin либо ее аналоги.
Теперь перейдем к самому разрабатываемому приложению. Если говорить о его реализации на C#, то для соединения с базой данных используется MySQLConnector/NET, отображение таблицы в БД производится стандартным методом. А далее мы также можем опять же идти двумя путями. Первый — программное обновление и добавление данных через адаптер MySqlDataAdapter с использованием представления в компоненте DataGridView. Давайте подробнее рассмотрим этот вариант. Допустим, вы подключились к БД, выбрали нужную таблицу и отобразили ее в DataGridView. Обновление полей существующего товара можно произвести следующим образом:
((DataTable)dataGridView1.DataSource).Rows[i][18] = baseId [i];
Именно такая запись является верной, хотя многие начинающие сталкиваются с трудностями из-за непонимания, вводя строки:
dataGridView1.Rows[i].Cells[18].Value = baseId [i];
Этот вариант неверен, потому как программно меняет записи только в элементе отображения, но не самой таблице с данными. А для добавления строк используем схожую конструкцию:
((DataTable) dataGridView1.DataSource).Rows.Add(baseId[i], category[i]);
В данном случае строчки кода набраны просто для примера, в котором показано, что добавление записей производится из неких массивов и ставятся, к примеру, внутри циклов.
Произведя необходимые изменения нужно обновить таблицу или таблицы данных, используя конструкцию кода, который выносится либо в отдельную функцию, либо вписывается в нужное место:
DataTable changes = data.GetChanges(); da.Update(changes); data.AcceptChanges(); … где изначально до этого были определены: private DataTable data; private MySqlDataAdapter da;
Наиболее частая ошибка при программном обновлении таблиц БД в данном случае MySQL, и добавления в них новых записей — duplicate entry. Если объяснять ее суть простыми словами, то эта ошибка возникает при обновлении либо добавлении записей в ключевые поля таблицы для случаев, когда идентичные записи в этих полях уже существуют.
Например, если у вас в качестве ключевого указано поле с именами артикулов товаров, то в таблице не может быть двух товаров с одинаковыми артикулами. Иначе говоря, каждый артикул должен быть уникальным. При обновлении подобным образом и возникновении ошибки duplicate entry сам процесс обновления тут же прекратится. Ситуацию можно обойти, вписав строку…
da.ContinueUpdateOnError = true;
Указатель ContinueUpdateOnError, установленный в true, позволяет продолжать действие обновления (функции Update()) в случае возникновения ошибок. По умолчанию он установлен как false.
Рассмотренный выше метод не очень удобен в рамках операции добавления (Add()), например, для случаев, когда у вас имеется таблица с большим количеством полей, а вам нужно заполнить выборочно только несколько из них. В результате, нужно составлять строку, учитывающую иногда все имеющиеся поля. Также этот метод будет громоздок, если вы хотите найти необходимый артикул товара и заменить в нем некоторые записи, в результате чего без дополнительных циклов и встроенных в них конструкций if-else не обойтись.
Если не привязываться к представлению в DataGridView и использованию MySqlDataAdapter, то обновление таблиц БД можно производить напрямую с помощью класса MySqlCommand. Он в любом случае используется хотя бы при том же открытии в DataGridView нужной таблицы (применяется метод ExecuteReader()), но мы пойдем дальше.
MySqlCommand позволяет выполнять базовые командные SQL-запросы INSERT, UPDATE и DELETE при использовании его собственного метода ExecuteNonQuery(). Выглядеть все может таким образом. В примере мы читаем данные из таблицы, названной dataGridViewExcel, в которую загружен Excel-файл и обновляем/вносим данные в таблицу ‘products’ нашей БД ‘myDataBase’. Сразу предупрежу, что данный код работать не будет из-за ошибки duplicate entry.
private MySqlConnection conn; private MySqlCommand incom1; private MySqlCommand incom2; …. //делаем коннект к БД if (conn != null) conn.Close(); string connStr = String.Format("server={0};user id={1}; password={2}; database=mysql; pooling=false", "localhost" , "root", ""); try { conn = new MySqlConnection(connStr); conn.Open(); } catch (MySqlException ex) { MessageBox.Show("Ошибка соедиенения с сервером: " + ex.Message); } … //запускаем цикл for (int I = 0; i < dataGridExcel.Rows.Count - 1; i++) { //обновляем данные incom1 = new MySqlCommand("UPDATE `myDataBase`.`products` SET name=@k1, picture=@k2 WHERE name=@k0", conn); incom1.Parameters.AddWithValue("@k0", dataGridViewExcel.Rows[i].Cells[0].Value.ToString()); incom1.Parameters.AddWithValue("@k1", dataGridViewExcel.Rows[i].Cells[1].Value.ToString()); incom1.Parameters.AddWithValue("@k2", dataGridViewExcel.Rows[i].Cells[2].Value.ToString()); incom1.ExecuteNonQuery(); //добавляем данные incom2 = new MySqlCommand("INSERT INTO `myDataBase`.`products` (`name`,`picture`) VALUES (@k1,@k2);", conn); incom2.Parameters.AddWithValue("@k1", dataGridViewExcel.Rows[i].Cells[1].Value.ToString()); incom2.Parameters.AddWithValue("@k2", dataGridViewExcel.Rows[i].Cells[2].Value.ToString()); incom2.ExecuteNonQuery(); }
Но уже в данном представлении вы можете убедиться, что этот вариант с использованием MySqlCommand более ёмок и позволяет нам напрямую общаться с таблицей БД и ее конкретными полями. Но как быть в данном случае с возникновением ошибки duplicate entry? На самом деле все решается очень просто, если вы поместите блоки кода с обновлением и добавлением в конструкции try-catch. Это работает фактически также как и в случае включения режима обновления в случае ошибок из предыдущего случая.
private MySqlConnection conn; private MySqlCommand incom1; private MySqlCommand incom2; …. //делаем коннект к БД if (conn != null) conn.Close(); string connStr = String.Format("server={0};user id={1}; password={2}; database=mysql; pooling=false", "localhost" , "root", ""); try { conn = new MySqlConnection(connStr); conn.Open(); } catch (MySqlException ex) { MessageBox.Show("Ошибка соедиенения с сервером: " + ex.Message); } … //запускаем цикл for (int I = 0; i < dataGridExcel.Rows.Count - 1; i++) { try { incom1 = new MySqlCommand("UPDATE `myDataBase`.`products` SET name=@k1, picture=@k2 WHERE name=@k0", conn); incom1.Parameters.AddWithValue("@k0", dataGridViewExcel.Rows[i].Cells[0].Value.ToString()); incom1.Parameters.AddWithValue("@k1", dataGridViewExcel.Rows[i].Cells[1].Value.ToString()); incom1.Parameters.AddWithValue("@k2", dataGridViewExcel.Rows[i].Cells[2].Value.ToString()); incom1.ExecuteNonQuery(); } catch {} try{ incom2 = new MySqlCommand("INSERT INTO `myDataBase`.`products` (`name`,`picture`) VALUES (@k1,@k2);", conn); incom2.Parameters.AddWithValue("@k1", dataGridViewExcel.Rows[i].Cells[1].Value.ToString()); incom2.Parameters.AddWithValue("@k2", dataGridViewExcel.Rows[i].Cells[2].Value.ToString()); incom2.ExecuteNonQuery(); } catch {} }
Топорный:), но действенный метод. Что касается сравнения обновления БД по времени с использованием первого или второго метода, которые мы описали… существенной разницы не обнаружено.
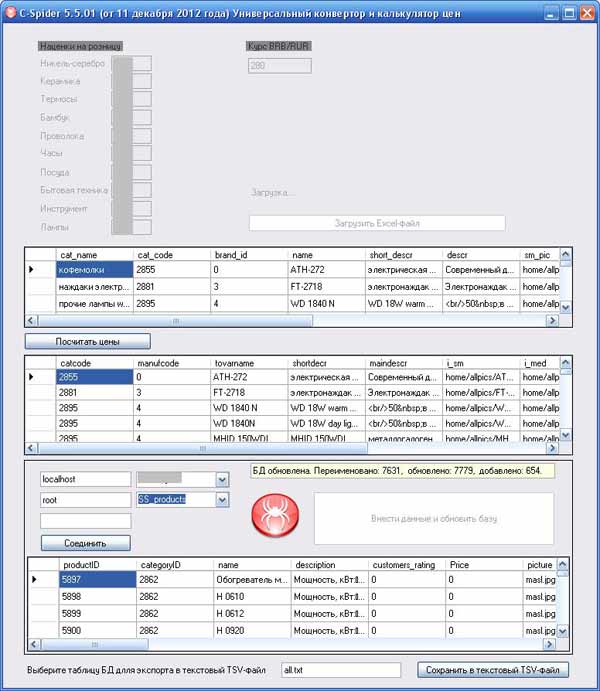
Одна из моих программ-конверторов, данные берутся из Excel-файла, пересчитываются цены и перераспределяются разделы для каталога товаров, затем все экспортируется в БД интернет-магазина.
Работа с BLOB-полями (MySQL, C#)
Не смотря на довольно спорные преимущества использование BLOB-полей в базах данных MySQL, их можно встретить довольно часто. BLOB (Binary Large Object) — это специальный тип данных, который может хранить в себе различную информацию (изображения, видео, текст, программы, архивы) в двоичном представлении. Наиболее часто в вебе он используется для хранения картинок внутри таблиц БД, но и не только, например, вы можете сохранять в нем целые страницы и т.п. В этой ситуации я сразу предупрежу, что сталкивался с BLOB только в режимах конвертирования таблиц чужих БД в свои, у себя я BLOB никогда не использую, за исключением одного заказа 2010 года по стеганогрфии в BMP:). Это трогать не будем:), да, там и вопрос был вовсе не в BLOB-полях, а в реализации шифрования md5... с последующем замещении младших битов в BMP-файлы. Но мы не об этом... Опишу, пожалуй, типичные траблы.
Вообще, в стандартных ситуациях хранение картинок внутри таблиц в BLOB-полях ведет больше к раздутию объема этих самых таблиц. Если говорить о хранении текста в BLOB тут тоже преимущество спорное, поскольку нужно будет специальным образом настраивать поиск по сайту.
С точки зрения PHP в Интернете есть множество информации по работе с BLOB, извлечения/загрузки картинок и тому подобного. Поэтому данный аспект мы затрагивать не будем. Чуть хуже обстоят дела с информацией по работе с BLOB-полями на C#, хотя на самом деле ничего особенно сложного в этом нет, нужно только осуществить грамотное преобразование двоичных данных в нужное представление и обратно (если мы говорим о тексте).
Например, я считывал на C# через MySQL Connector BLOB-поля с текстом и отображал в таблице с названием DataGridViewString по колонкам, используя следующую конструкцию (мне нужно было видеть текст и вносить в него изменения, это реальная ситуация, задачей было прописать alt для картинок в базе с 5000 товаров):
private DataTable data_bin; private MySqlDataAdapter da; private MySqlCommandBuilder cb; … //делаем коннект к БД … data_bin = new DataTable(); da = new MySqlDataAdapter( "SELECT * FROM `myDataBase`.`products`", conn); cb = new MySqlCommandBuilder(da); da.Fill(data_bin); DataColumn column0 = data_bin.Columns.Add("name(string)", typeof(string)); foreach (DataRow rows in data_bin.Rows) { rows[column0] = Encoding.UTF8.GetString((byte[])rows["name"]); } DataColumn column1 = data_bin.Columns.Add("picture(string)", typeof(string)); foreach (DataRow rows in data_bin.Rows) { rows[column1] = Encoding.UTF8.GetString((byte[])rows["description"]); } data_bin.Columns.Remove("name"); data_bin.Columns.Remove("description"); DataGridViewString.DataSource = data_bin;
Принцип действия этого кода довольно прост, то есть в таблицу с бинарными данными добавляются новые колонки, в которые записывается уже преобразованные в текст, а бинарные удаляются.
Запись же в BLOB-поля производится по одному из способов, которые описаны в предыдущем ответе с одной лишь разницей, что вы должны помещать бинарные данные. Обратное преобразование, думаю вопросов не вызовет, это описано в любом справочнике: byte[] name1 = Encoding.UTF8.GetBytes(dataGridViewString.Rows[i].Cells[1].Value.ToString().Trim());
Если говорить об импорте/экспорте изображений из/в BLOB, то для первого случая (импорта) мы немного преобразуем предыдущий код, а именно, возьмем из таблицы БД поля с названием артикулов, считаем изображения в буфер, создадим стрим, и сохраним наши картинки в файлы с расширением jpg:
data_bin = new DataTable(); da = new MySqlDataAdapter( "SELECT `name`,`picture` FROM `myDataBase`.`products`", conn); cb = new MySqlCommandBuilder(da); da.Fill(data_bin); foreach (DataRow rows in data_bin.Rows) { string str = "C:\\"+Encoding.UTF8.GetString((byte[])rows["name"])+".jpg"; byte[] Img = (byte[])rows["picture"]; FileStream fs = new FileStream(str, FileMode.CreateNew, FileAccess.Write); fs.Write(Img, 0, Img.Length); fs.Flush(); fs.Close(); }
В этом коде представлен самый простой случай и по умолчанию подразумевается, что все файлы изображений являются Jpeg. В более сложных ситуациях необходимо использовать библиотеку Image.Drawing для преобразования бинарных данных в изображения. И этот вариант окажется лучшим, поскольку там имеется метод Save с принудительной конвертацией под заданный формат, например, для нашего случая:
Image image1 = new Bitmap(new MemoryStream((byte[])rows["picture"]); image1.Save(str, System.Drawing.Imaging.ImageFormat.Jpeg);
На самом деле вариантов может быть довольно много, поэтому экспериментируйте. Суть понятна — читаем данные в буфер byte[], создаем стрим (например, MemoryStream), пишем данные из буфера в стрим, затем перегоняем данные в нужный класс для работы с изображениями, производим конвертацию в нужный формат и сохраняем.
Что касается чтения файлов и преобразования их в бинарный вид, то тут обратное движение. В данном случае я покажу довольно стандартную функцию.
byte[] ReadImageToBytes(string sPath) { byte[] data = null; //FileInfo для получения размера файла FileInfo fInfo = new FileInfo(sPath); long numBytes = fInfo.Length; //Открываем поток FileStream для чтения файла FileStream fStream = new FileStream(sPath, FileMode.Open, FileAccess.Read); //Используем BinaryReader и читаем данные в буфер byte[] BinaryReader br = new BinaryReader(fStream); data = br.ReadBytes((int)numBytes); return data; }
А, в общем и целом, использование BLOB-полей в большинстве стандартных ситуаций вряд ли можно назвать оправданным шагом.
Одна из моих программ по комплексному автоматизированному обслуживанию интернет-магазинов (в данном случае двух), в БД которых используются BLOB-поля. Для внесения данных требуются преобразования в двоичное представление и из него.
На сим всё, первая часть «Реального программирования» завершена.
|